
Google-ის TurboQuant AI-კომპრესიის ალგორითმს LLM-ის მეხსიერების მოხმარების 6-ჯერ შემცირება შეუძლია
მაშინაც კი, თუ გენერაციული ხელოვნური ინტელექტის მოდელების შიდა მუშაობის პრინციპების შესახებ ბევრი არაფერი იცით, ალბათ გსმენიათ, რომ მათ დიდი მოცულობის მეხსიერება სჭირდებათ. სწორედ ამიტომ, ამჟამად თითქმის შეუძლებელია ოპერატიული მეხსიერების (RAM) თუნდაც მცირე ბარათის ყიდვა ისე, რომ არ გაგატყავონ. Google Research-მა ცოტა ხნის წინ წარადგინა TurboQuant, კომპრესიის ალგორითმი, რომელიც ამცირებს დიდი ენობრივი მოდელების (LLM) მეხსიერების კვალს, ამავდროულად ზრდის სიჩქარეს და ინარჩუნებს სიზუსტეს.
TurboQuant-ის მიზანია “key-value” (გასაღები-მნიშვნელობა) ქეშის ზომის შემცირება, რომელსაც Google ადარებს „ციფრულ შპარგალკას“, რომელიც ინახავს მნიშვნელოვან ინფორმაციას, რათა მისი ხელახლა გამოთვლა არ გახდეს საჭირო. ეს შპარგალკა აუცილებელია, რადგან, როგორც ხშირად ვამბობთ, LLM-ებმა სინამდვილეში არაფერი იციან; მათ შეუძლიათ შექმნან შთაბეჭდილება, თითქოს რაღაც იციან ვექტორების გამოყენებით, რომლებიც ტოკენიზებული ტექსტის სემანტიკურ მნიშვნელობას ასახავს. როდესაც ორი ვექტორი მსგავსია, ეს ნიშნავს, რომ მათ კონცეპტუალური მსგავსება აქვთ.
მაღალგანზომილებიანმა ვექტორებმა, რომლებსაც შეიძლება ასობით ან ათასობით ემბედინგი ჰქონდეთ, შესაძლოა აღწერონ კომპლექსური ინფორმაცია, როგორიცაა გამოსახულების პიქსელები ან დიდი მონაცემთა ნაკრები. ისინი ასევე იკავებენ დიდ მეხსიერებას და ზრდიან key-value ქეშის ზომას, რაც აფერხებს წარმადობას. მოდელების ზომის შესამცირებლად და ეფექტურობის გასაზრდელად, დეველოპერები იყენებენ კვანტიზაციის ტექნიკას, რათა ისინი უფრო დაბალი სიზუსტით ამუშაონ. ნაკლი ის არის, რომ შედეგები უარესდება — ტოკენების შეფასების ხარისხი იკლებს. TurboQuant-ის შემთხვევაში, Google-ის ადრეული შედეგები აჩვენებს წარმადობის 8-ჯერ ზრდას და მეხსიერების გამოყენების 6-ჯერ შემცირებას ზოგიერთ ტესტში, ხარისხის დაკარგვის გარეშე.
კუთხეები და შეცდომები
TurboQuant-ის გამოყენება AI მოდელზე ორეტაპიანი პროცესია. მაღალი ხარისხის კომპრესიის მისაღწევად, Google-მა შეიმუშავა სისტემა სახელწოდებით PolarQuant. ჩვეულებრივ, AI მოდელებში ვექტორები კოდირებულია სტანდარტული XYZ კოორდინატების გამოყენებით, მაგრამ PolarQuant გარდაქმნის ვექტორებს პოლარულ კოორდინატებად დეკარტის სისტემაში. ამ წრიულ ბადეზე ვექტორები ორ ინფორმაციამდე დადის: რადიუსი (მონაცემთა ძირითადი სიძლიერე) და მიმართულება (მონაცემების მნიშვნელობა).
Google გვთავაზობს საინტერესო რეალურ ანალოგიას ამ პროცესის ასახსნელად. ვექტორული კოორდინატები ჰგავს მითითებებს: ტრადიციული კოდირება შეიძლება იყოს „წადი 3 კვარტალი აღმოსავლეთით, 4 კვარტალი ჩრდილოეთით“. მაგრამ დეკარტის კოორდინატების გამოყენებით, ეს უბრალოდ არის „წადი 5 კვარტალი 37 გრადუსიანი კუთხით“. ეს ნაკლებ ადგილს იკავებს და სისტემას მონაცემთა ნორმალიზაციის ძვირადღირებული ნაბიჯების შესრულებისგან ათავისუფლებს.
PolarQuant ასრულებს კომპრესიის დიდ ნაწილს, მაგრამ მეორე ნაბიჯი ასწორებს ხარვეზებს. მიუხედავად იმისა, რომ PolarQuant ეფექტურია, მან შეიძლება შექმნას ნარჩენი შეცდომები. Google გვთავაზობს ამის გამოსწორებას ტექნიკით, რომელსაც ეწოდება Quantized Johnson-Lindenstrauss (QJL). ეს მოდელს ამატებს 1-ბიტიან შეცდომის გამოსწორების ფენას, რომელიც თითოეულ ვექტორს ერთ ბიტამდე ამცირებს (+1 ან -1), ამავდროულად ინარჩუნებს აუცილებელ ვექტორულ მონაცემებს, რომლებიც აღწერს ურთიერთკავშირებს. შედეგი არის უფრო ზუსტი „ყურადღების ქულა“ (attention score) — ეს არის ფუნდამენტური პროცესი, რომლის საშუალებითაც ნეირონული ქსელები წყვეტენ, რომელი მონაცემია მნიშვნელოვანი. თუ მეტი დეტალი გაინტერესებთ, წინასწარი სამეცნიერო ნაშრომი ხელმისაწვდომია ჩამოსატვირთად.
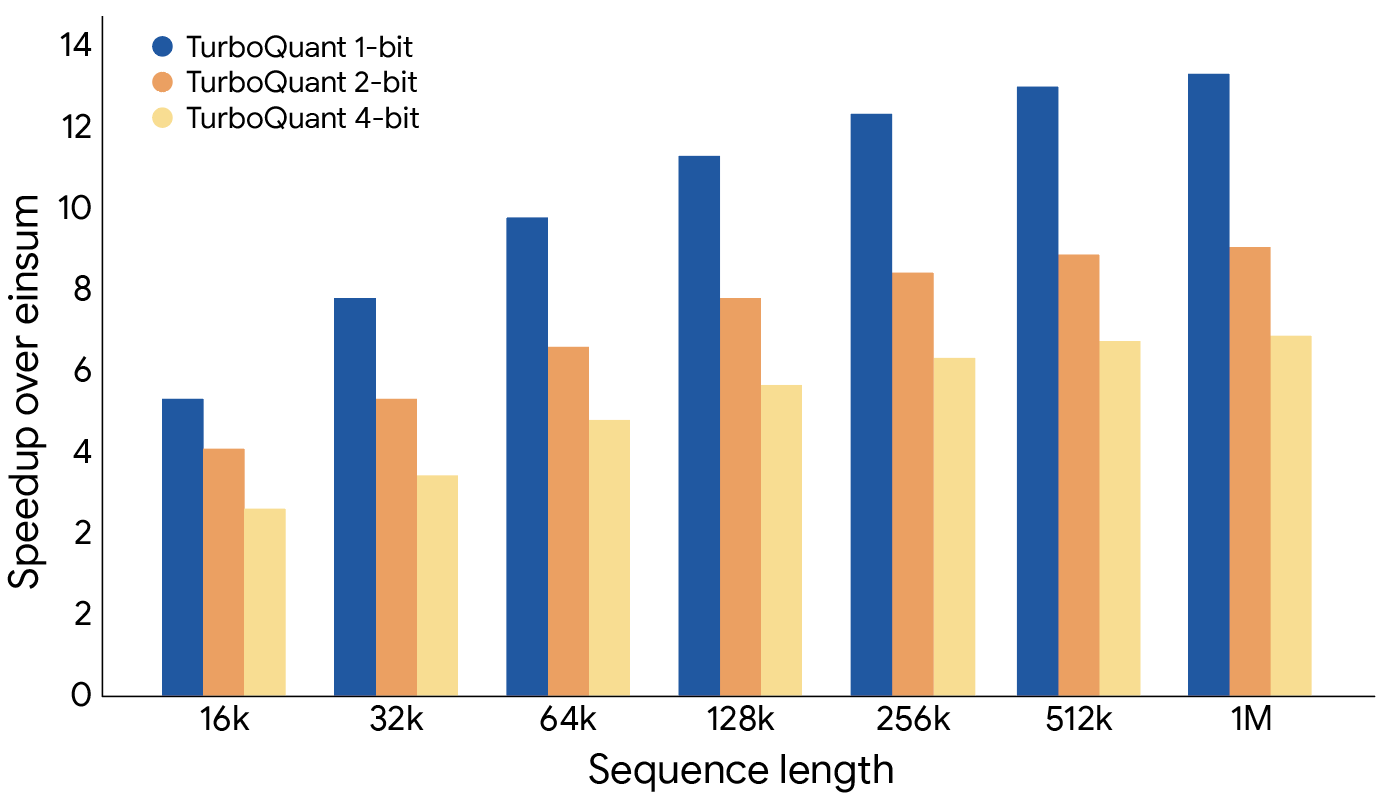
მაშ, მუშაობს თუ არა მთელი ეს მათემატიკა? Google აცხადებს, რომ მათ გამოსცადეს ახალი ალგორითმული კომპრესია გრძელი კონტექსტის მქონე ბენჩმარკების სერიაში, Gemma-სა და Mistral-ის ღია მოდელების გამოყენებით. TurboQuant-ს, როგორც ჩანს, ყველა ტესტში იდეალური საბოლოო შედეგები ჰქონდა, თანაც key-value ქეშში მეხსიერების გამოყენება 6-ჯერ შეამცირა. ალგორითმს შეუძლია ქეშის კვანტიზაცია მხოლოდ 3 ბიტამდე დამატებითი წვრთნის გარეშე, ამიტომ მისი გამოყენება არსებულ მოდელებზეც შეიძლება. „ყურადღების ქულის“ გამოთვლა 4-ბიტიანი TurboQuant-ით ასევე 8-ჯერ უფრო სწრაფია 32-ბიტიან არაკვანტიზებულ გასაღებებთან შედარებით Nvidia H100 აქსელერატორებზე.
დანერგვის შემთხვევაში, TurboQuant-მა შეიძლება AI მოდელების მუშაობა უფრო იაფი გახადოს და შეამციროს მეხსიერების მოთხოვნილება. თუმცა, ამ ტექნოლოგიის შემქმნელმა კომპანიებმა შესაძლოა გამოთავისუფლებული მეხსიერება უფრო რთული მოდელების ასამუშავებლად გამოიყენონ. სავარაუდოდ, ორივეს ნაზავს ვიხილავთ, მაგრამ მობილურმა ხელოვნურმა ინტელექტმა შესაძლოა ყველაზე დიდი სარგებელი მიიღოს. სმარტფონის აპარატურული შეზღუდვების გათვალისწინებით, TurboQuant-ის მსგავს კომპრესიის ტექნიკებს შეუძლიათ გააუმჯობესონ შედეგების ხარისხი თქვენი მონაცემების ღრუბელში (cloud) გაგზავნის გარეშე.
გაზიარება:
დაკავშირებული პოსტები

ათეისტი ევოლუციონისტი მეცნიერი Anthropic-ის Claude-ს 72 საათის განმავლობაში ესაუბრა და ახლა სჯერა, რომ ის ცნობიერია

სემ ალტმანის პროექტი World ვერიფიკაციის ტექნოლოგიას გაცნობის აპლიკაციებში ნერგავს

YouTube-მა სმარტ ტელევიზორებზე 90-წამიანი გამოუტოვებელი რეკლამების ჩვენება დაიწყო

Telegram-მა მესამე მხარის კლიენტების მომხმარებლების მონიშვნა დაიწყო. ასევე, მესენჯერმა მიიღო ხელოვნური ინტელექტის რედაქტორი და ბოტების ფაბრიკა

CERN-ში მონაცემთა მასივების გასაფილტრად ჩიპებში ინტეგრირებულ სპეციალურ AI-მოდელებს იყენებენ
