საინტერესო
ყველას ნახვა




ხელოვნური ინტელექტი
ყველას ნახვა
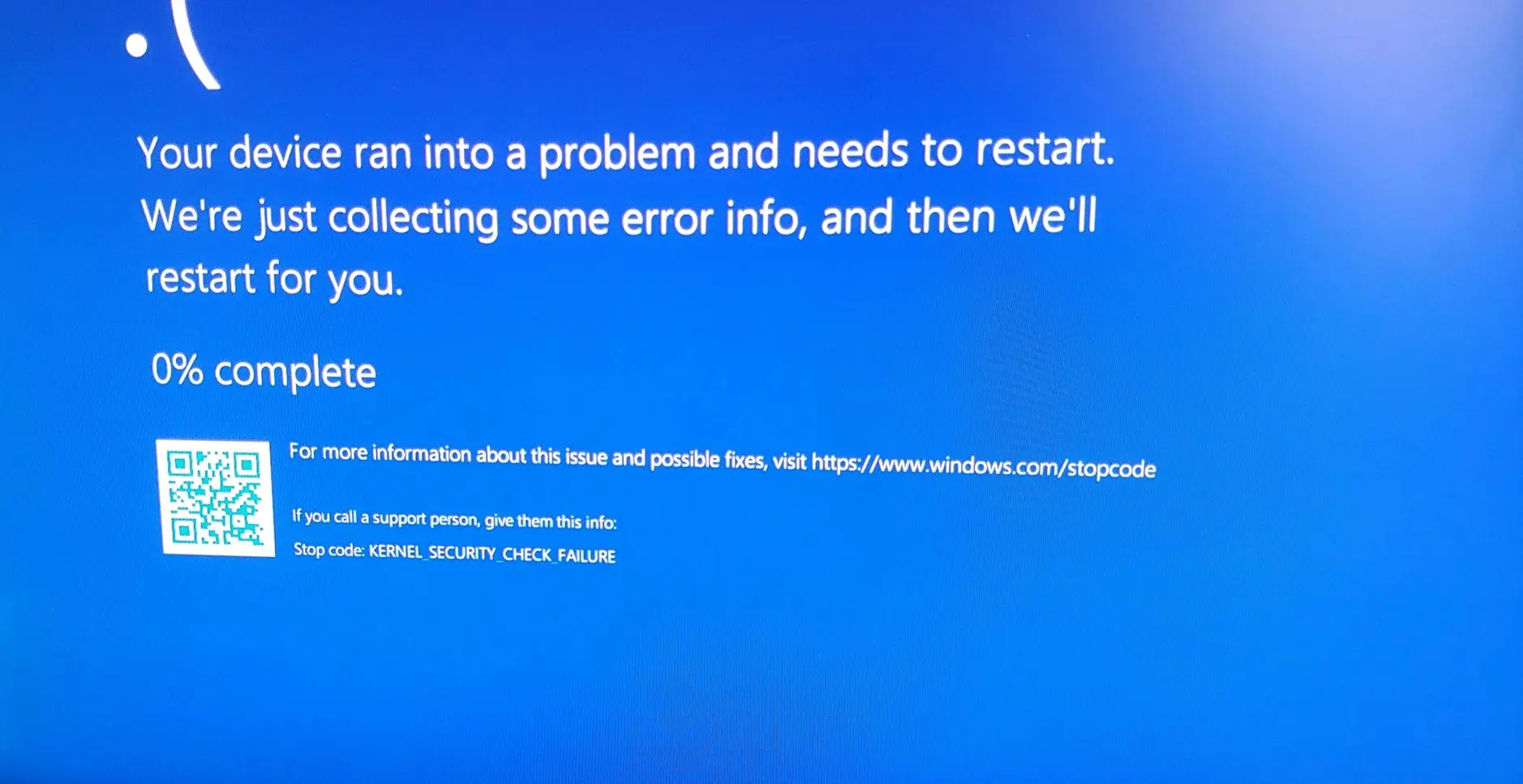
Anthropic: DeepSeek-ი, Moonshot-ი და MiniMax-ი ფარულად წვრთნიდნენ თავიანთ მოდელებს Claude-ის პასუხებზე
Anthropic-ის განცხადებით, მათ აღმოაჩინეს, რომ სამი ჩინური AI-ლაბორატორია — DeepSeek-ი, Moonshot-ი და MiniMax-ი — მასობრივად მოიპოვებდა Claude-ის პასუხებს, რათა მათზე საკუთარი მოდელები გაეწვრთნათ. ჯამში მათ 16 მილიონზე მეტი მოთხოვნა დააგენერირეს დაახლოებით 24 000 ყალბი ანგარიშის მეშვეობით. ამ მეთოდს დისტილაცია ეწოდება: იღებთ ძლიერ მოდელს, აწვდით ათასობით პრომპტს, აგროვებთ პასუხებს და იყენებთ მათ, როგორც სასწავლო მონაცემებს თქვენი […]

Anthropic-მა Cloudflare-ისა და CrowdStrike-ის აქციები დააგდო Claude Code Security-ის წარდგენით

OpenAI თანამშრომლების სათვალთვალოდ ChatGPT-ს იყენებს — ხელოვნური ინტელექტი მათ Slack-სა და ელფოსტას კითხულობს

Google თავის საუკეთესო პროდუქტიულობის ინსტრუმენტებს ფასიანს ხდის

სტარტაპმა Taalas-მა ნეიროქსელი ჩიპში ჩააშენა და რეკორდული 17 000 ტოკენი წამში მიიღო
ჰარდი
ყველას ნახვა
Apple-ის ახალი გეგმები: ჭკვიანი სათვალე, AI კულონი და კამერიანი AirPods
Bloomberg-ის ინფორმაციით, Apple აჩქარებს მუშაობას სამ ახალ AI მოწყობილობაზე, რომლებიც Siri-ს ციფრული ასისტენტის გარშემო იქნება აგებული. 1. ჭკვიანი სათვალე (Smart Glasses) Apple-ის სათვალეს არ ექნება ეკრანი (განსხვავებით Vision Pro-სგან). ის კონკურენციას გაუწევს Meta Ray-Ban სათვალეებს. მოწყობილობა აღჭურვილი იქნება კამერებით გარემოს აღქმისთვის (“Visual Intelligence”) და ხმოვანი მართვით. 2. AI კულონი (Pendant) Humane AI Pin-ის მსგავსი მოწყობილობა, […]

2026 წელს Nvidia არცერთ ახალ ვიდეობარათს არ გამოუშვებს

ინსაიდერები: Apple ქმნის ტანსაცმელზე დასამაგრებელ AI მოწყობილობას სამკერდე ნიშნის სახით

Sony-მ LinkBuds Clip Open წარადგინა — თავისი პირველი ყურსასმენები-კლიფსები

Intel-მა Core Ultra Series 3 (Panther Lake) პროცესორები წარადგინა. ეს არის 18A ტექნოლოგიურ პროცესზე დაფუძნებული პირველი მასობრივი CPU-ები, რომლებიც აშშ-შია შექმნილი და წარმოებული
სოფტი
ყველას ნახვა
8 წლის შემდეგ, AsteroidOS 2.0 გამოვიდა – ახალი სიცოცხლე თქვენი სმარტ-საათისთვის
8 წლის შემდეგ, Linux-ზე დაფუძნებული ღია ოპერაციული სისტემა AsteroidOS დაბრუნდა განახლებული ვერსიით 2.0. ეს პროექტი მიზნად ისახავს ძველ სმარტ-საათებს ახალი სიცოცხლე შესძინოს და მომხმარებლებს Google-ისა და Apple-ის დახურული სისტემების ალტერნატივა შესთავაზოს. რა არის AsteroidOS? AsteroidOS არის სრულად ღია კოდის მქონე OS, რომელიც აგებულია Linux-ის ბაზაზე (OpenEmbedded). ის ორიენტირებულია კონფიდენციალურობაზე – არანაირი ტელემეტრია და იძულებითი ღრუბლოვანი […]

მიტჩელ ჰაშიმოტომ Vouch წარადგინა — ახალი ინსტრუმენტი Open Source სამყაროში “AI ნაგვის” წინააღმდეგ

League of Legends-ის სრული განახლება 2027 წელს გამოვა

Half-Life 3: ჭორები Steam Machine-თან ერთად 2026 წლის გაზაფხულზე გამოშვების შესახებ

Android Show: XR, Gemini და პარტნიორობა — Google-ის ახალი სტრატეგიის სამი საყრდენი
მეცნიერება
ყველას ნახვა
ბიზნესი
ყველას ნახვა
ტექნოლოგიური სფეროს კრიზისი: მასშტაბური გათავისუფლებები გრძელდება
Futurism-ის ახალი ანგარიშის თანახმად, ტექნოლოგიურ სექტორში დასაქმებულები სერიოზული გამოწვევების წინაშე დგანან. მხოლოდ ოქტომბრის თვეში აშშ-ის ტექნოლოგიურმა ინდუსტრიამ რეკორდული რაოდენობის – 33,281 თანამშრომელი გაათავისუფლა. მთავარი დეტალები: 📉 სტატისტიკა: მიმდინარე წელს უკვე 141,159 სამუშაო ადგილი გაუქმდა (შარშანდელთან შედარებით 20,000-ით მეტი). 🤖 მიზეზები: კომპანიები მასობრივად ამცირებენ ხარჯებს და ნერგავენ ხელოვნურ ინტელექტს (AI), რასაც “ქამრების შემოჭერას” და დაქირავების შეჩერებას […]

Samsung-ის ხელმძღვანელები და თანამშრომლები დააკავეს ჩინეთში 10-ნმ DRAM ტექნოლოგიის გაჟონვის გამო

უკრაინელები პირველები მიიღებენ Starlink-ის “პირდაპირ მობილურზე” სატელიტურ სერვისს ევროპაში

Starlink, უფრთხილდი: Amazon უშვებს თავის პირველ ზესწრაფ სატელიტურ ქსელს